Rows: 2,240
Columns: 9
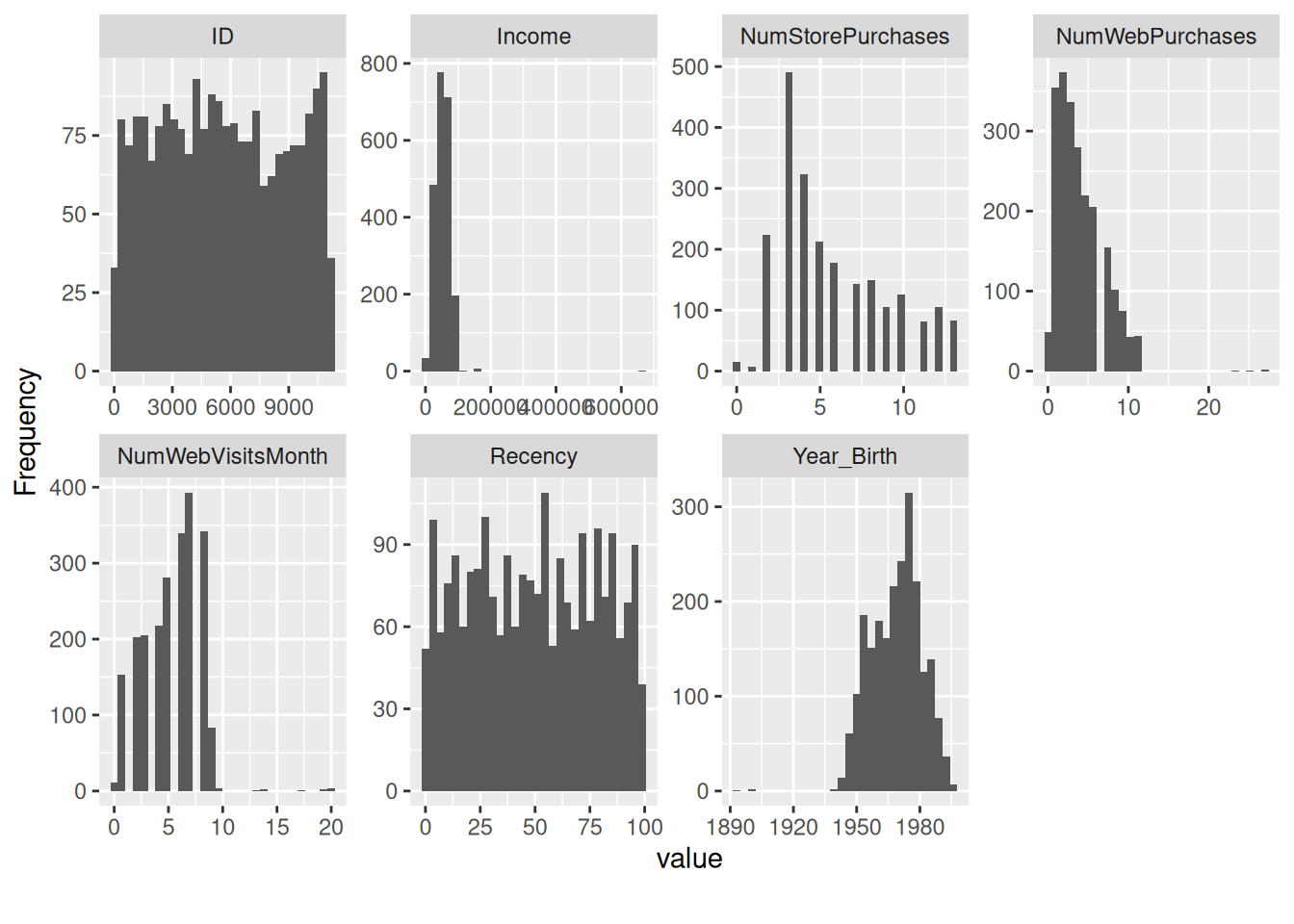
$ ID <int> 5524, 2174, 4141, 6182, 5324, 7446, 965, 6177, 4855,…
$ Year_Birth <int> 1957, 1954, 1965, 1984, 1981, 1967, 1971, 1985, 1974…
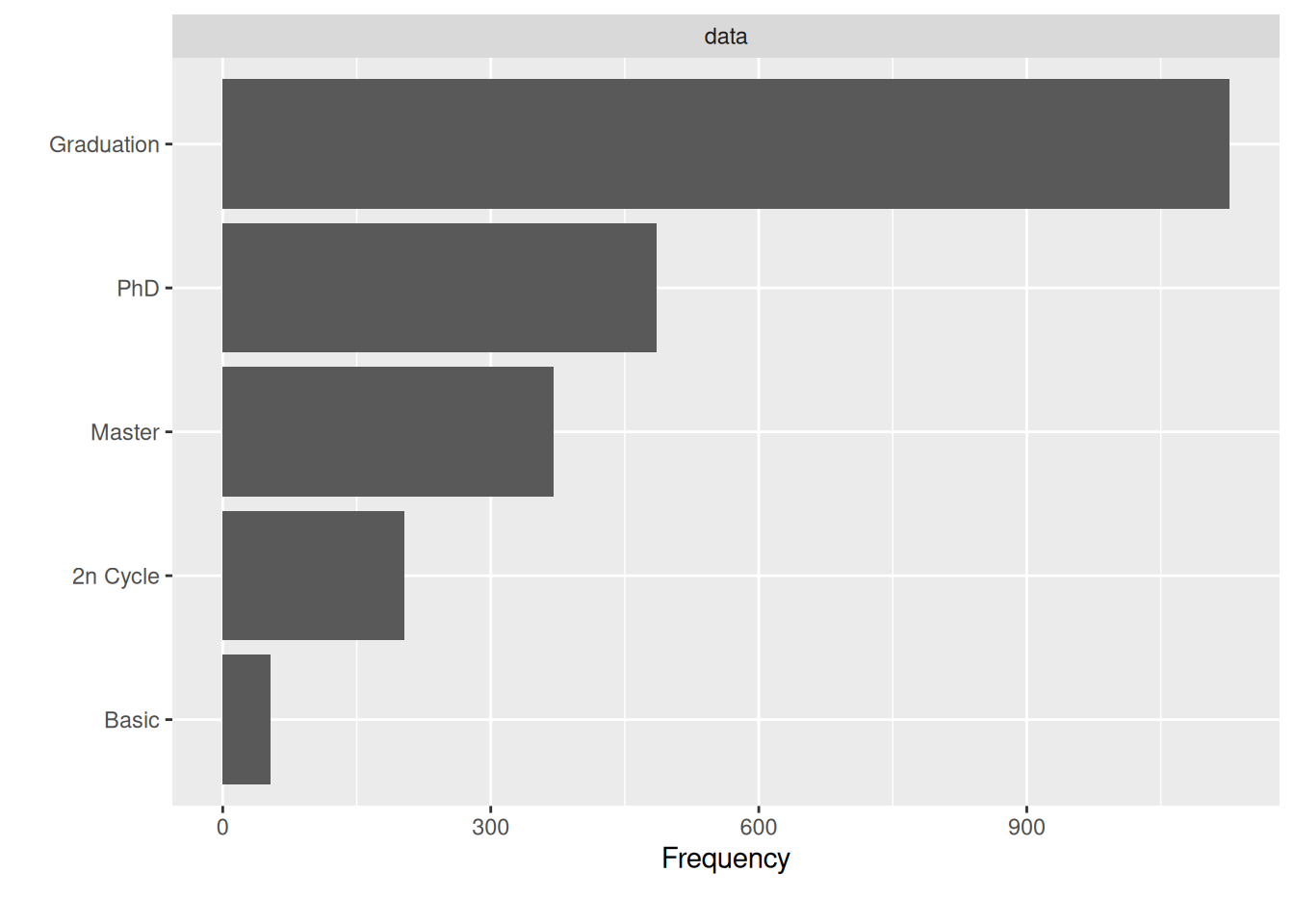
$ Education <chr> "Graduation", "Graduation", "Graduation", "Graduatio…
$ Income <int> 58138, 46344, 71613, 26646, 58293, 62513, 55635, 334…
$ Dt_Customer <chr> "9/4/2012", "3/8/2014", "8/21/2013", "2/10/2014", "1…
$ Recency <int> 58, 38, 26, 26, 94, 16, 34, 32, 19, 68, 11, 59, 82, …
$ NumWebPurchases <int> 8, 1, 8, 2, 5, 6, 7, 4, 3, 1, 1, 2, 3, 6, 1, 7, 3, 4…
$ NumStorePurchases <int> 4, 2, 10, 4, 6, 10, 7, 4, 2, 0, 2, 3, 8, 5, 3, 12, 3…
$ NumWebVisitsMonth <int> 7, 5, 4, 6, 5, 6, 6, 8, 9, 20, 7, 8, 2, 6, 8, 3, 8, …